図1. 音源の構造
|
||||||||
| フレームあり フレームなし | ||||||||
参照:
説明
| インタフェースの概要 | |
| PhraseEventType | フレーズイベントの種類を定義します。 |
| PhraseTrackListener | フレーズシーケンサからのイベントを待ち受けるリスナを実装するためのインタフェースです。 |
| クラスの概要 | |
| AudioPhrase | Phraseはフレーズデータを保持するためのクラスです。 |
| AudioPhraseTrack | AudioPhraseTrackはオーディオデータを再生するためのクラスです。 |
| Phrase | Phraseはフレーズデータを保持するためのクラスです。 |
| PhrasePlayer | PhrasePlayerクラスは、端末の音源内に構成可能な「仮想音源」トラックまたは「オーディオデコーダ」を管理します。 |
| PhraseTrack | PhraseTrackはフレーズデータを再生するためのクラスです。 |
フレーズプレイヤー関連のクラスおよびインタフェースを提供します。
MIDP1.0仕様 microJBlendのマルチメディア拡張クラスライブラリでは、下記3つのメディア再生機能があります。
フレーズプレイヤーは、ゲームや音楽アプリケーションなどでの使用が想定される複数のメロディや音声を、独立、非同期に重畳再生することが可能なコンポーネントです。Java アプリケーションはフレーズプレイヤーを用いて、BGMと効果音メロディの同時再生や、複数のメロディを組み合わせた楽曲再生などを行うことができます。
フレーズデータではデータ中にユーザーイベントを埋め込むことが可能です。再生中にユーザーイベントが埋め込まれている時点に達したとき、Javaアプリケーションにイベントが通知されます。このイベント通知を利用して、Javaアプリケーション側で音声に同期した画面表示が可能となります。
フレーズプレイヤーではフレーズデータに加えて、オーディオデータ(ADPCMデータ)を再生することが可能です。
ここではメロディデータを再生するための機構について説明します。
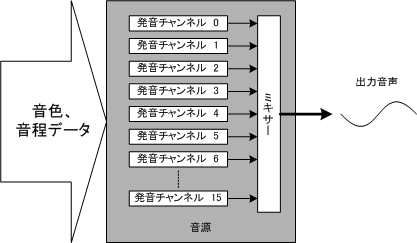
ひとつの音符を再生するためには、指定された音色、音高で音を発するような機構が必要になり、これを発音チャネルと呼びます。発音チャネルを1つ以上持ち、それぞれの出力をまとめて最終的な出力とするミキサー、及びそれらの制御機構を含めた発音システム全体は音源と呼ばれます。たとえば、「16和音」という仕様は、発音チャネルを16個持った音源を意味しています。また、音源が内蔵している発音チャネルの数は「最大同時発音数」と呼ばれます。16和音の音源モデルを図1に示します。
図1. 音源の構造
メロディデータはひとつひとつの音符の総体である楽譜の情報を意味していて、この中には下記の項目などが時間軸に沿ったシーケンスデータとして記述されています。
これを再生するためには、タイマー制御によって順に制御情報を読み出し、音源に対して制御命令を発行する機構が必要になります。この機構はシーケンサと呼ばれます。シーケンサが処理する様子を図2に示します。
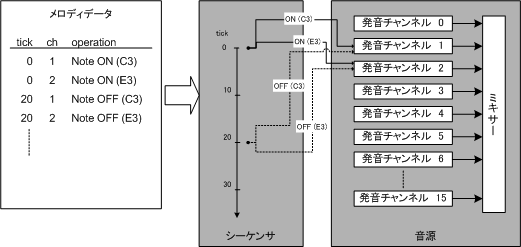
図2. シーケンサの処理モデル(メロディ再生モード)
図2の例では、メロディデータのシーケンスデータは時刻(tick)ごとに、「発音チャネル」、「音程」、及び「発音・消音」などの書式で記述されています。シーケンサは、個々のシーケンスデータを読み取り、指定された時刻に、指定された処理を、指定された発音チャネルに設定します。メロディを再生するためには、上記のように音源とシーケンサの組が必要となります。以降、この組をトラック(またはシーケンストラック)と呼びます。
ここではフレーズ再生モードでの音源の使用方法について説明します。
フレーズ再生は複数のメロディ(以後、区別の便宜上フレーズと呼びます)を独立に再生するモードです。このため複数のトラックが必要となります。ところが、携帯電話などのシステムにおいて音源は通常一つしかありません。そのため、フレーズ再生においては、音源の制御機構において、発音チャネルをいくつかのグループに分けて、それぞれをひとつの独立した音源として扱うことによって、仮想的に複数のトラックを構成することにします。図3はサウンド再生時に、最大同時発音数16の音源をそれぞれ4音の仮想的な音源4つに分割した例となっています。
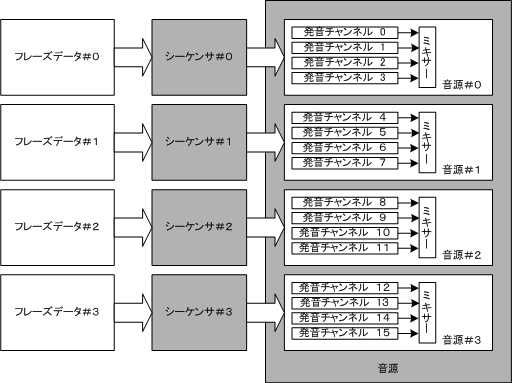
図3. 音源とシーケンサの関係(フレーズ再生モード)
それぞれの仮想トラックの最大同時発音数は、実装依存になります。フレーズデータは、この前提条件のもとに制作される必要があります。フレーズプレイヤーでは使用可能な仮想トラックの数をJavaアプリケーションが実行時に取得できるようにしています。
個々の仮想トラックについて割り当てる発音チャネルを動的に変更することはできません。そのかわり、トラックを複数組み合わせてそれらを一つのトラックのようにみなし、同期させて再生できます。
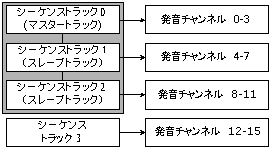
図4. 複数のトラックの同期再生
図4では、トラック0、1、2を組み合わせて、12音のトラックとし、トラック3とあわせて計2つのトラックのように制御する様子を示しています。複数のトラックを組み合わせるときは、便宜上、一つのトラックを「マスタートラック」、それ以外を「スレーブトラック」とします。マスタートラックの再生に同期してスレーブトラックも再生されます。図4ではトラック0をマスターとし、トラック1、2をスレーブとした例となっています。この状態でトラック0を再生すると、トラック1、2も同時に再生されます。
トラックは重複して組み合わせることはできません。たとえば、トラック0、1、2を組み合わせて、かつトラック2、3も組み合わせることはできません。ただし、重複さえしなければ任意の組み合わせが可能とします。たとえば、フレーズ再生モードにおいても、すべてのトラックを組み合わせて一つのトラックとすることも可能です。
複数のトラックを組み合わせる場合においても、個々のトラックには独立にフレーズデータを設定します。
フレーズデータが音色と音程であるのに対し、オーディオデータ(ADPCMデータ)は波形データが元になっています。図5は、4つの仮想トラックに加え、ひとつのオーディオデコーダを持つシステムの例です。オーディオ再生のための機構(オーディオデコーダ)はフレーズ再生のための機構とは別に用意されるのでオーディオ再生はフレーズ再生と同時に実行可能です。
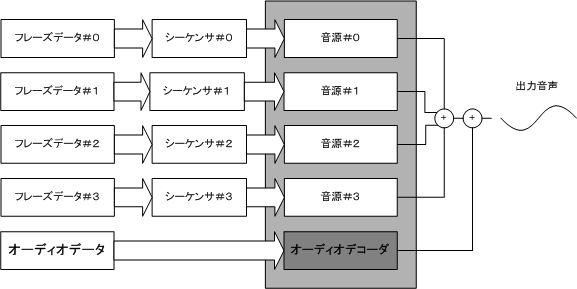
図5. フレーズプレイヤー内部構成
フレーズ再生と同様に、いくつのオーディオデコーダが使用可能かについては実装依存です。フレーズプレイヤーでは使用可能なオーディオデコーダの数をJavaアプリケーションが実行時に取得できるようにしています。また、複数のオーディオデコーダの存在を前提として、フレーズデータと同様なオーディオデコーダ同士の同期再生機能のモデルを定義しています。
メディアプレイヤーはメロディ再生モードで音源を使用します。メロディ再生モードは、1つのメロディを再生するモードとします。この場合、トラックはひとつあればよいことになります。図2はメロディ再生モードでの構成例です。一方、フレーズプレイヤーはサウンド再生、および音声再生のモードで音源を使用します。図5はフレーズプレイヤーでの音源の使用例です。
このように、メディアプレイヤーとフレーズプレイヤーでは音源の使用方法が異なります。そして通常の端末でのハードウェア構成では、2つの再生モードを両立させることはできないため、メディアプレイヤーとフレーズプレイヤーは同時に使用することはできません。
「フレーズプレイヤー」を構成する主要なクラスとインタフェースの関連について図6に示します。
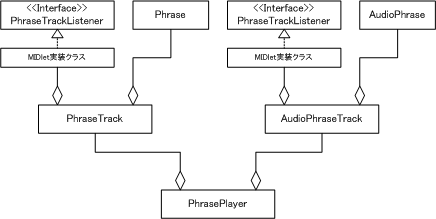
図6. フレーズプレイヤー主要クラス構成
フレーズデータを再生するときの手順は概略次のようになります。
PhrasePlayerのスタティックメソッドgetPlayer()でPhrasePlayerオブジェクトを取得します。
PhrasePlayerのgetAudioTrackCount()メソッドを呼び出して、使用可能なトラックの数が取得できます。
再生するフレーズデータをコンストラクタに指定して、Phraseオブジェクトを生成します。
PhrasePlayerのgetTrack()またはgetTrack(int track)メソッドでPhraseTrackオブジェクトを取得します。
取得したPhraseTrackのsetPhrase()メソッドでPhraseオブジェクトを設定します。また、setEventListener()メソッドでPhraseTrackListenerインタフェースを実装したリスナを登録します。複数のトラックを同期させて再生する場合は、スレーブとなるPhraseTrackに対して、setSubjectTo()メソッドでマスタートラックとなるPhraseTrackとの関連付けを行います。
フレーズデータが設定されているPhraseTrackは、play()メソッドで再生できます。play()には、通常のバージョンに加えて繰り返しの指定が可能なバージョンが用意されています。また、再生途中や再生に先立って、音量と左右の定位をそれぞれsetVolume()とsetPanpot()メソッドで設定したり、mute()メソッドで消音することが可能です。同期再生させるには、マスタートラックとなっているPhraseTrackのplay()を呼び出します。
再生状態にあるPhraseTrackは、stop()メソッドで再生を停止できます。また、pause()とresume()メソッドでそれぞれ一時停止と再開が可能です。同期再生を停止するには、マスタートラックとなっているPhraseTrackのstop()を呼び出します。
再生を停止したPhraseTrackに対して、removePhrase()メソッドでその時点のフレーズ設定を解除できます。そして新たなフレーズをsetPhrase()メソッドで設定することも可能です。
使い終わったPhraseTrackは、PhrasePlayerのdisposeTrack()メソッドを呼び出してフレーズプレイヤーに返します。
PhrasePlayerのdisposePlayer()メソッドを呼び出すことにより、PhrasePlayerオブジェクトを破棄できます。
物理的に利用可能なトラック数の範囲内で、上記4から8までの手順を用いて複数のPhraseTrackを生成し、それぞれ独立に再生させることができます。また、個々のPhraseTrackにおいて、上記の手順5から8を繰り返して別のフレーズデータを再生させることが可能です。
オーディオデータを再生するには上記のフレーズデータの再生手順において、Phraseオブジェクトの代わりにAudioPhraseオブジェクトを生成します。そしてPhrasePlayerのgetTrack()メソッドでPhraseTrackを取得する代わりに、getAudioTrack()メソッドでAudioPhraseTrackオブジェクトを取得します。AudioPhraseをAudioPhraseTrackに設定して再生する方法は、PhraseをPhraseTrackで再生する方法と同様です。
|
||||||||
| フレームあり フレームなし | ||||||||